Introduction
Semantic search over documents is increasingly vital for knowledge-driven apps. In this post, we explore a system that extends RAG beyond a single PDF: it fetches candidate files from the web or your database, processes and embeds their content, and streams relevance scores back to the user in real time.
1. Motivation and Problem Statement
Most RAG demos show you asking questions of one PDF at a time. That works if you know exactly which file holds the answer. In practice, you often need to search across many documents some in your local storage, some out on the web.
How can we:
- Discover candidate files relevant to a query (e.g., via Google Search or your own API)?
- Process each document into retrievable chunks and embeddings?
- Combine semantic similarity with GPT-based ranking to surface the most relevant snippets?
- Serve results with low latency under load and keep costs in check?
This system meets these needs with a cache-first, queued-processing architecture, streaming results back as they arrive.
2. High-Level Architecture
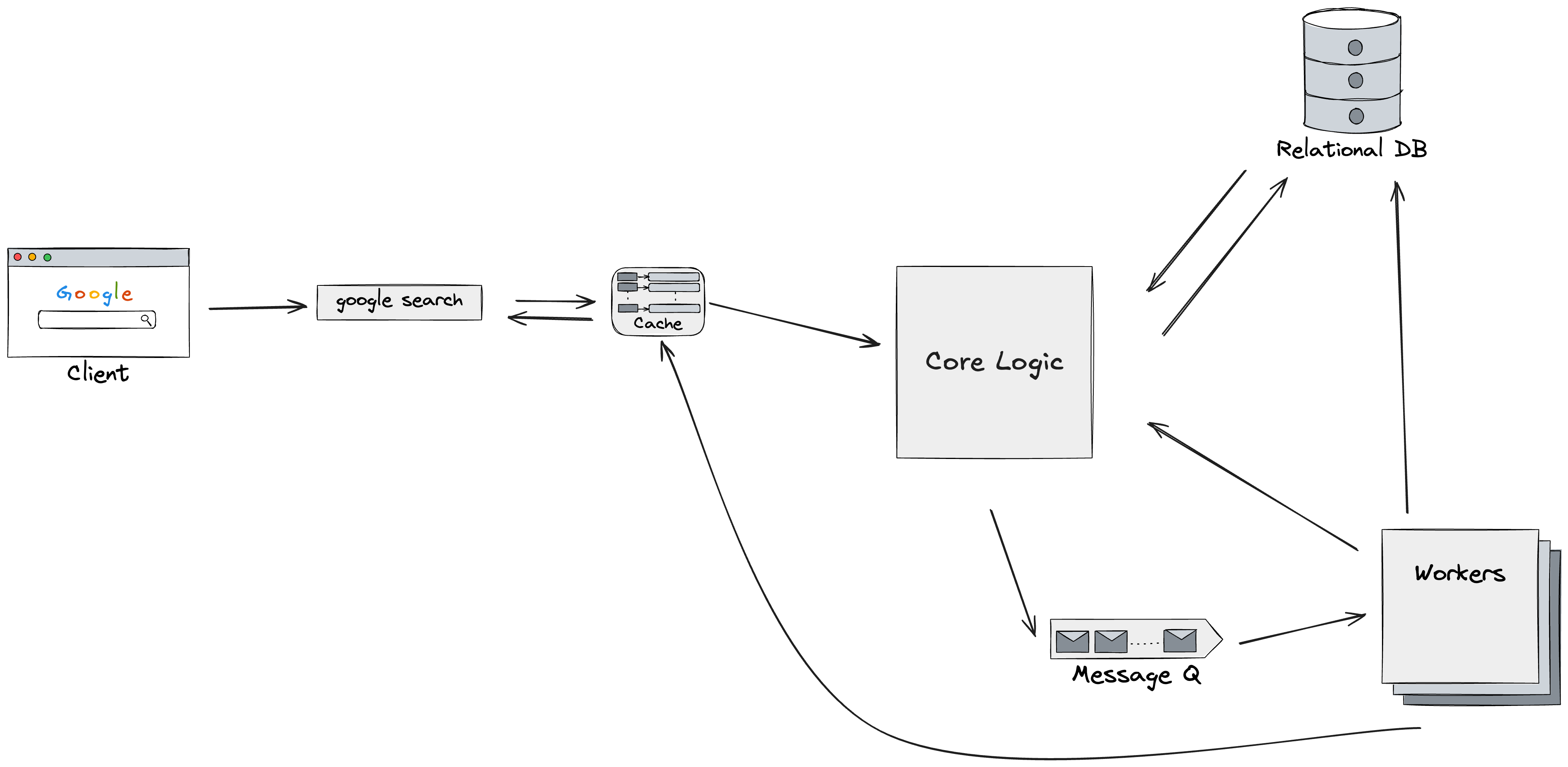
- Client (Next.js App Router)
- Provides a search UI.
- Calls a REST endpoint on
/api/search. - Uses Server-Sent Events (SSE) or HTTP streaming to update relevance scores in real time.
- Core Logic
- Cache layer: Redis stores entries for fast hits.
- Decision flow: on cache miss, look up embeddings in Supabase; if missing, enqueue work; otherwise compute similarity and rank.
- Relational DB & Vector Store (Supabase)
- Stores document metadata, file URLs, text chunks, and embeddings.
- Choice of Supabase: built‑in storage, Postgres for metadata, and pgvector extension for vector queries.
- Workers (Node.js + LangChain)
- Use a simple in-built queue for task scheduling.
- For each new URL or PDF: download, extract text, chunk, call OpenAI embeddings API, and save to Supabase.
- Message Queue (In-Built)*
- Decouples on‑demand search from heavy embedding work.
- Enables horizontal scaling of workers.
3. Design Decisions & Trade‑Offs
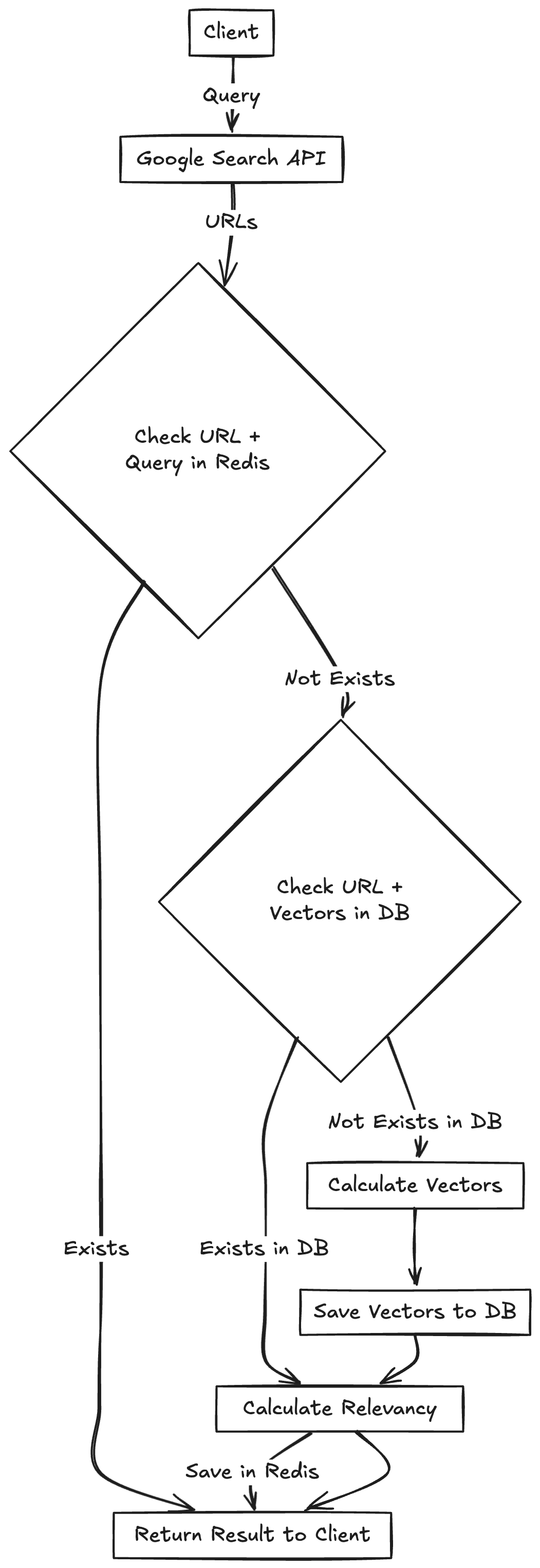
3.1 Entry Point: Google Search vs. Custom Connector
- Google Search API gives broad web coverage but adds cost and rate limits.
- Custom connector (e.g., your internal doc store) offers tighter control and security.
- Decision: start with Google for prototyping, allow pluggable connectors for future needs.
3.2 Cache Strategy (Redis)
- Cache key:
hash(search_query + url + chunk_size) - TTL: configurable (e.g., 1 hour) to balance freshness vs. cost.
- Why Redis: in‑memory, atomic ops, streaming pub/sub for SSE triggers.
3.3 Chunking and Embedding
- Chunk size: ~500 tokens with 50-token overlap to preserve context.
- Embedding model:
text-embedding-3-smallvs. larger variants—trade latency vs. accuracy. - LangChain automates text splitting and vectorization.
3.4 Storage: Supabase + pgvector
- Embeddings upserted into a Vector column.
- Use
vector_cosine_distanceorivfflatindexes for fast nearest‑neighbor. - Alternative: specialized vector DBs (Pinecone, Weaviate).
- Decision: Supabase simplifies infra and costs for MVP.
3.5 Streaming API (SSE)
- REST + SSE gives progressive UI updates.
- Each time a worker completes a document or GPT ranking finishes, core logic publishes an event on Redis pub/sub.
- Client listens and updates the table of relevancy scores in real time.
3.6 GPT‑Based Reranking
-
Initial similarity gives coarse ordering.
-
Passing top K (e.g., 5) snippets to GPT with a prompt like:
"Rank these snippets by relevance to the query: ..."
-
Trade‑off: extra cost for higher precision.
-
Fallback: skip rerank for ultra‑low latency mode.
4. API Specification
POST /api/search?source=google
Content-Type: application/json
{ "query": "Explain LangChain architecture" }
--stream--
event: partial
data: { "url": "https://...pdf", "snippet": "LangChain is...", "score": 0.82 }
event: partial
data: { ... }
event: done
sourceparameter:googleorcustom.- Streaming: send
partialevents as each document ranking arrives, then a finaldoneevent.
5. Implementation Highlights
- Next.js Route Handler under
/app/api/search/route.js. - Redis Client with
ioredisfor cache lookups and pub/sub. - In-built queue for job scheduling
- Worker Script (e.g.,
worker.js) usesLangChain PDFLoader,RecursiveCharacterTextSplitter, andOpenAIEmbeddings. - Supabase integration with
@supabase/supabase-js. - SSE Streaming via
ReadableStreamin the route handler.
Worker Task Details
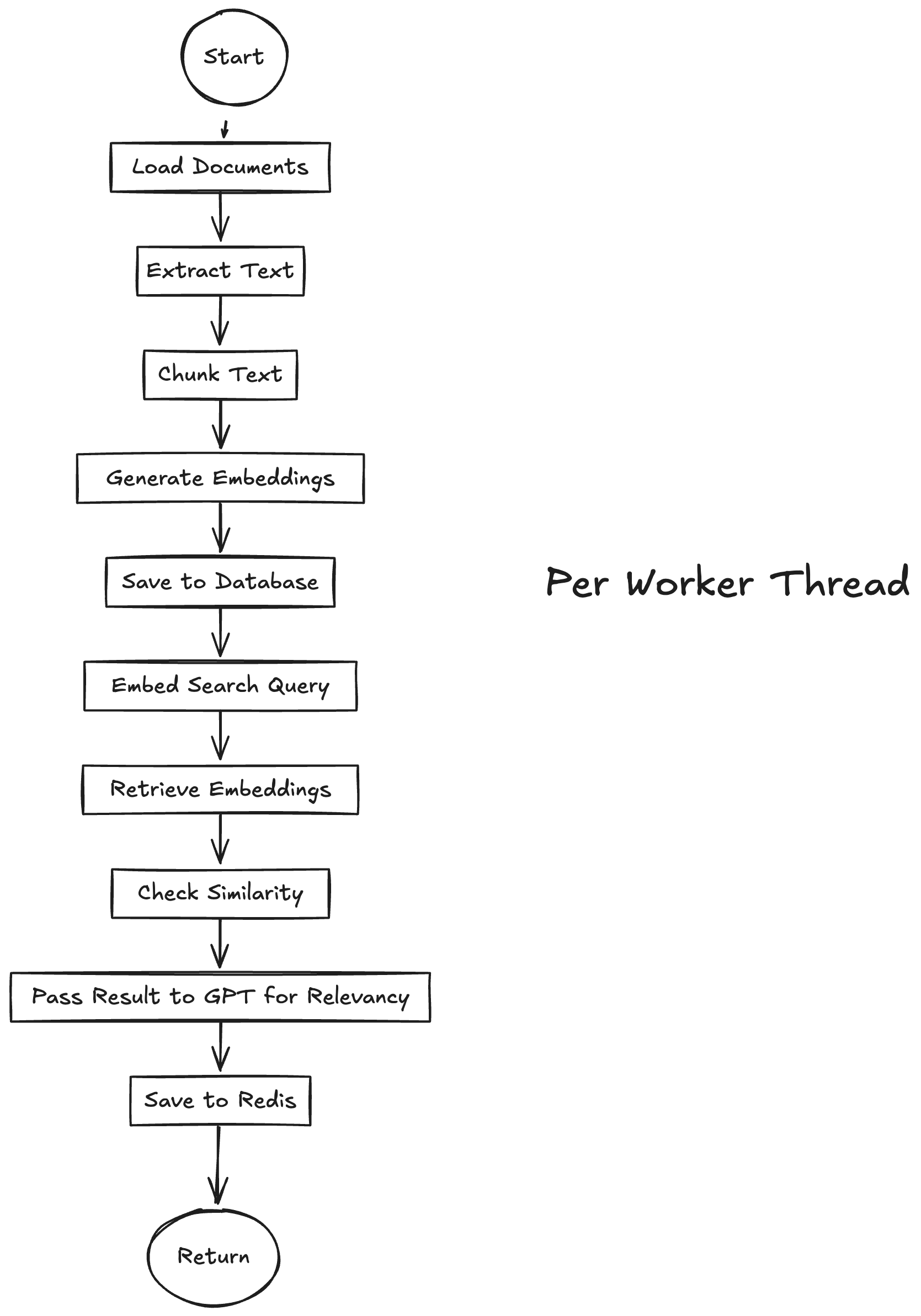
After receiving a job from the in‑built queue, each worker executes the following steps:
- Fetch PDF
- Download the file from the provided URL or Supabase storage.
- Verify file integrity (checksum or HTTP status).
- Load and Extract Text
- Use
LangChain PDFLoaderto parse the PDF pages. - Convert pages into raw text blocks.
- Use
- Chunking
- Initialize
RecursiveCharacterTextSplitterwith a 500‑token chunk size and 50‑token overlap. - Split the raw text into coherent chunks preserving semantic context.
- Initialize
- Embedding Generation
- For each text chunk, call
OpenAIEmbeddings.embedText(chunk)to produce a vector. - Batch embedding calls where possible to reduce latency and cost.
- For each text chunk, call
- Upsert to Supabase
- Insert or update each chunk’s text, metadata (page, position), and embedding vector into the
documents_chunkstable in Supabase. - Ensure
ON CONFLICTupsert logic uses(document_id, chunk_index)as the unique key.
- Insert or update each chunk’s text, metadata (page, position), and embedding vector into the
- Progress Publishing
-
After each chunk upsert, publish a Redis pub/sub message on channel
worker:progress:{ "event": "chunk_processed", "url": "<source_url>", "chunk_index": 3 } -
Core logic listens to these events and streams partial updates to the client via SSE.
-
- Initial Similarity Scoring
- Once all embeddings for a document are stored, compute cosine similarity between the query embedding and each chunk vector using Supabase’s
vector_cosine_distance. - Select the top K chunks (e.g., K=5) by similarity score.
- Once all embeddings for a document are stored, compute cosine similarity between the query embedding and each chunk vector using Supabase’s
- GPT-Based Reranking
- Format a prompt bundling the original query and the top K snippets.
- Call
OpenAI.ChatCompletionto rank snippets by relevance. - Parse the response and generate a refined ordering with updated scores.
- Final Result Publication
- Save the reranked snippets and their scores into Redis under the key
results:<query_hash>. - Publish a
worker:doneevent on Redis pub/sub with the final batch of data.
- Save the reranked snippets and their scores into Redis under the key
- Cleanup and Metrics
- Emit internal logs or metrics (execution time, embedding cost) to a monitoring system.
- Acknowledge job completion in the in‑built queue.
6. Future Enhancements
- Pluggable document connectors (S3, Google Drive).
- Advanced chunk merging: semantic boundary detection.
- Multi‑modal support (images, audio transcripts).
- Real‑time embeddings update with user feedback loop.
7. Conclusion
This system demonstrates how to build a resilient, high‑throughput PDF search platform that:
- Discovers candidate files via web or custom sources.
- Processes large batches of documents asynchronously.
- Embeds and ranks content semantically.
- Streams results to deliver instant feedback.
With Next.js, Supabase, Redis, and LangChain, you can bootstrap powerful document‑driven applications with minimal ops overhead. The complete code and deployment instructions are linked below—feel free to clone and adapt for your own use case!
🚀 GitHub Repo with code samples and config files