Introduction
This project started as a take home assignment. The goal was to build a conversational interface that could generate and manage outreach sequences. These are the kinds of multi step follow ups you might send over a few days, with scheduled messages and edits along the way.
I treated it like a real system design problem. I broke the workflow into clear components, focused on separation of responsibilities, and built a backend that could take user input from a chat and turn it into structured, scheduled actions.
What came out of it is a semi agentic system. It supports a single turn of agency, meaning the user can express intent in natural language, and the system responds by creating or updating real deliverables like email steps. It does not plan or adapt over time, but the structure is in place for that to be added later.
In this post, I’ll walk through how I built it, why I made certain choices, and what I learned from designing a system that bridges conversation with execution.
🔗 Check the Loom demo and GitHub repo linked at the top of this post to see it in action.
The Problem
The goal was to create a system that takes a simple chat input something like "create a 3 step outreach for software engineers" and turns that into a live, editable sequence that can be scheduled and sent. The whole thing needed to happen inside one interface, without switching tools or relying on external schedulers.
This means connecting conversational input with structured backend logic. The user does not fill out a form. They describe their goal in their own words, and the system figures out what to do.
The key challenge was making that translation smooth and reliable, while giving the user full control over the final result.
User Flow
From a user's point of view, here is how the system works:
- Start a conversation: The user types something like "create a 3 step sequence for hiring backend engineers."
- System responds: The chat replies with a human readable message and also displays a structured, editable sequence.
- Review and edit: Each message can be tweaked inline. The user can change the subject, body, send day, or delete a step entirely.
- Confirm and publish: Once reviewed, the user confirms. The system stores the sequence and schedules the steps.
- Delivery and status: A background worker sends messages at the scheduled time and updates delivery status in the system.
Everything happens within the same chat workspace. No tabs. No context switching.
System Overview
The system has five main components:
- Chat interface – Built using Next.js and React, it handles user input and displays streaming responses.
- Sequence workspace – Renders sequence steps alongside the chat. Steps are editable and deletable.
- API gateway – A single route that handles chat messages, session management, and sequence commands.
- Sequence engine – Stores sequences, manages edits and versioning, and connects to the delivery queue.
- Delivery worker – Checks the queue, sends scheduled messages, retries on failure, and logs results.
Technical Overview
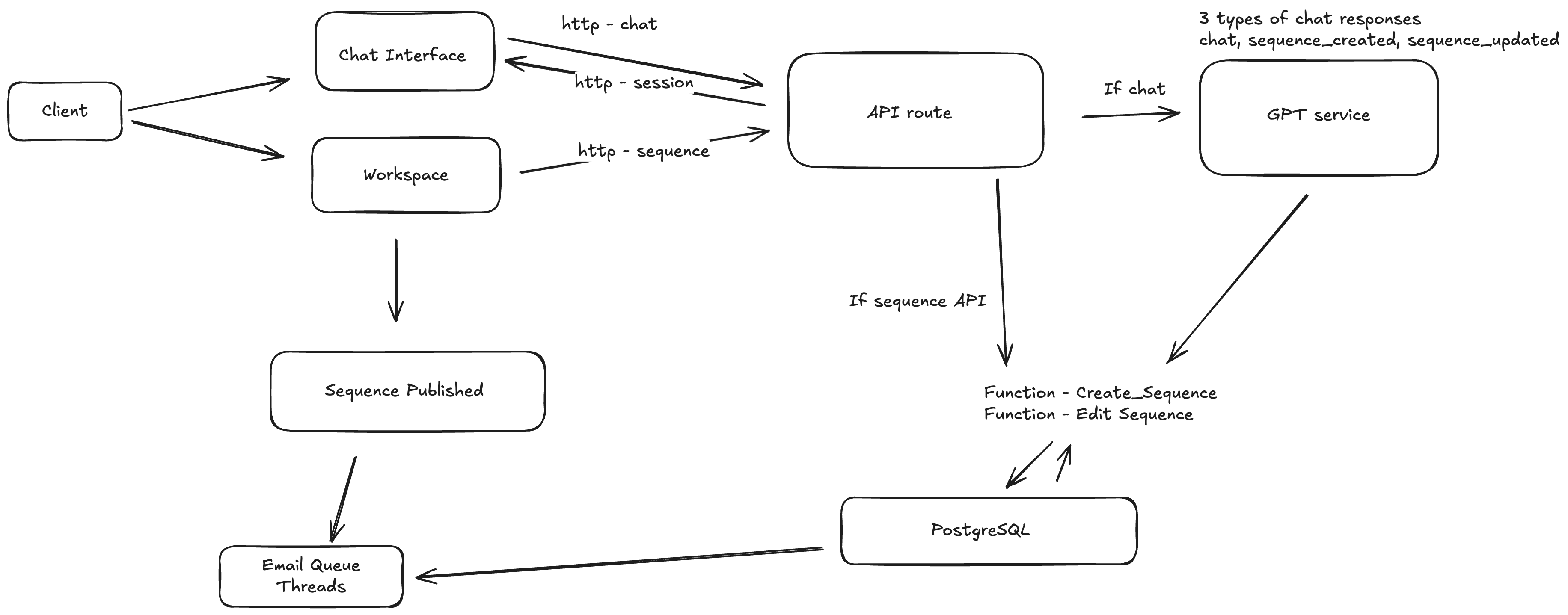
The backend exposes three main endpoints: /chat, /session, and /sequence. All user input routes through a common API handler, which either sends the input to the GPT service (to get a chat response and potential action) or to the sequence engine to handle publishing or editing.
Messages are interpreted into three types of responses: chat, sequence created, or sequence updated. These are rendered by the frontend and mapped to internal functions on the backend that manage sequence storage and scheduling.
A PostgreSQL queue tracks scheduled steps, and a delivery worker polls that queue to send messages and update delivery status. Edits, versions, and user confirmations are stored for traceability.
What Worked Well
- Keeping chat and sequence logic separate made the system easier to manage and debug.
- The PostgreSQL queue worked surprisingly well for controlling delivery windows and retries.
- Keeping the user in control was key. Even though the system generates drafts, nothing is sent without confirmation.
What Could Be Improved
- Right now, the system only supports single step interaction. It does not adapt or plan across multiple steps.
- Adding feedback loops like checking if a message was opened and suggesting a follow up would take the system closer to full autonomy.
- Extending to other delivery channels like LinkedIn or Slack would make the system more useful in different environments.
What I Learned
Designing around structured output from natural language input is a useful pattern. It forces you to think carefully about the boundary between user language and backend actions.
Building things in a modular way chat on one side, sequence logic on another, delivery in the background gave me more flexibility than I expected. It made testing and iteration faster.
Also, agentic does not have to mean complex. Even a single step system that can listen to a user and act on their intent is meaningful if it saves time and removes friction.
If you're curious about how each component works under the hood, how the queue was structured, how the worker runs, and how the data flows across the architecture keep reading. Below is a technical deep dive that covers it all in detail. Cause going deep is what we all like. 😉
Technical Deep Dive
High Level Architecture - This project doesn’t do low level. Neither do I.
This system is designed to support a single turn semi agentic outreach workflow from user conversation to scheduled message execution. Below is a component by component analysis based on the high level diagram:
1. Client → Chat Interface and Workspace
The client has two major UI surfaces:
- Chat Interface: where the user types a prompt like “create a 3 step sequence for backend engineers.”
- Workspace: where generated drafts appear and can be reviewed, edited, and published.
All interactions go through REST endpoints:
POST /chat: handles message promptsPOST /session: persists session statePOST /sequence: handles sequence creation, edits, and publish actions
2. Chat Interface → API Route → GPT Service
When a prompt is sent through /chat, the backend sends it to the GPT service. The GPT service returns one of three types of structured responses:
chat: plain text replysequence_created: structured response with stepssequence_updated: diffs or revisions
This response is parsed by the frontend to render updated UI elements.
3. Workspace → API → Sequence Engine
When a user edits a step or hits “publish,” the frontend sends it to /sequence. The backend routes it to either create_sequence() or edit_sequence() functions.
These insert rows into the database for:
- the sequence envelope
- individual steps (subject, body, offset)
- associated metadata like status, timestamps, or versioning info
4. PostgreSQL as the Central State and Queue
PostgreSQL stores:
- Active sessions and sequence metadata
- Version history per sequence
- A
queuetable that represents scheduled messages
Each message has:
sequence_id,step_idscheduled_at,status,retry_count- Soft flags for
failed,sent, orpending
5. Sequence Published → Email Queue Rows
Once a sequence is confirmed, each step is inserted into the queue table.
INSERT INTO sequence_queue (step_id, scheduled_at, status)
VALUES (uuid, NOW() + interval '2 days', 'pending');A worker polls this table based on scheduled time:
SELECT * FROM sequence_queue
WHERE scheduled_at <= NOW() AND status = 'pending';6. Worker Loop → SMTP → Status Update
The worker attempts delivery using an SMTP or email API. On success:
UPDATE sequence_queue SET status = 'sent', sent_at = NOW()
WHERE id = ...;On failure:
- It retries with exponential backoff
- After N attempts, flags the step as
failed - Sends logs or alerts if needed
7. Real Time Feedback and Logs
Logs are appended on every major event:
- Creation, editing, publishing
- Delivery attempt and result
- Errors or fallbacks
This structure provides full visibility for audit trails and future metrics (opens, clicks, etc).
Design Decisions
- PostgreSQL queue: chosen for simplicity, observability, and ease of inspection in a prototype setting
- Structured GPT response schema: ensures predictable backend actions
- Frontend ownership of edits: lets users refine without interrupting session state
This combination results in a reliable, traceable flow from chat to execution, while leaving room to add richer planning or channel support later.
Chat Input to Actionable Intent
User messages are sent to a backend route that handles both free form input and structured commands. A structured prompt guides the GPT service to return both natural responses and action metadata. The API routes this response to the appropriate handler based on the type: chat, sequence creation, or sequence update.
Sequence Creation and Storage
When a sequence is created, each step is stored as a row in the PostgreSQL database. Fields include message body, subject, delay offset, delivery type, and status. The system generates a version ID to track changes over time.
Queue Implementation Using PostgreSQL
Instead of Kafka or a message broker, a dedicated table acts as a job queue. Each row represents a message to be sent, marked by a future timestamp and a pending delivery status. This makes it easy to query upcoming jobs and manage retries directly within SQL.
Background Worker Design
A polling worker process runs on an interval, querying for messages whose scheduled time has arrived. When found, it sends the message using an SMTP or transactional API and updates the row status. Failures are retried with exponential backoff, and error states are logged for future handling.
Editable Frontend with Versioning
The workspace frontend lets users edit subject lines, body text, and timing inline. These changes are sent to the backend as JSON payloads. The backend logs the new version while maintaining previous ones, allowing for traceability and rollback.
Real Time Streaming and Intent Matching
The chat interface supports token streaming for fast feedback. On top of that, the model returns metadata that is parsed to determine if an actionable intent exists (e.g. create or update sequence). This allows the system to react dynamically while still keeping the user in control.
Logs, Delivery Tracking, and Extensibility
Each delivery is logged, along with metadata like timestamps, send result, and retry attempts. While currently limited to email, the system is structured to support other delivery channels by adding a simple abstraction around message handlers.
Final Thoughts
This project gave me a reason to design a full system end to end something that connects frontend input, backend logic, and delayed execution into one clean workflow.
It was a good exercise in turning a vague product idea into a working structure. There are lots of directions this could go next, but the current version already shows how powerful even a basic agentic system can be when everything is built with intent.
Thanks for reading. Peace ✌️